 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Language Modeling for Speech Recognition
Jan 25, 2000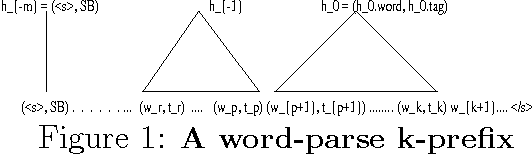

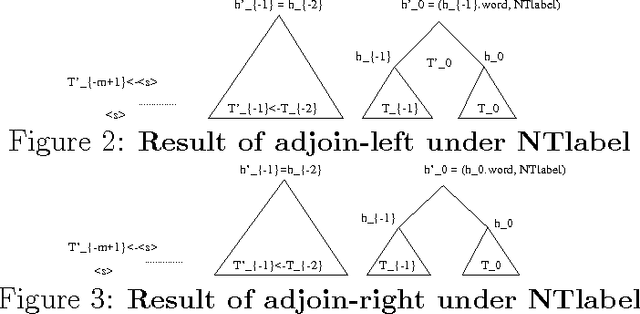
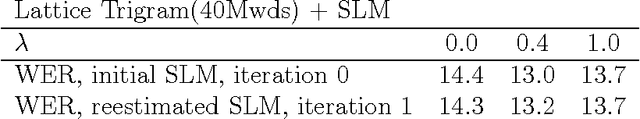
A new language model for speech recognition is presented. The model develops hidden hierarchical syntactic-like structure incrementally and uses it to extract meaningful information from the word history, thus complementing the locality of currently used trigram models. The structured language model (SLM) and its performance in a two-pass speech recognizer --- lattice decoding --- are presented. Experiments on the WSJ corpus show an improvement in both perplexity (PPL) and word error rate (WER) over conventional trigram models.
* 4 pages + 2 pages of ERRATA
Expoiting Syntactic Structure for Language Modeling
Jan 25, 2000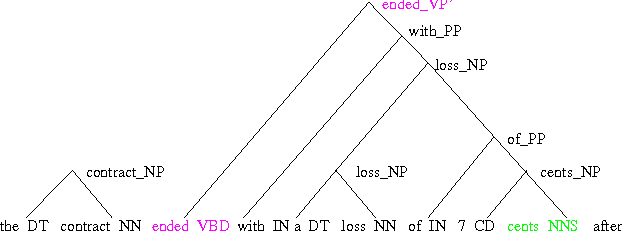
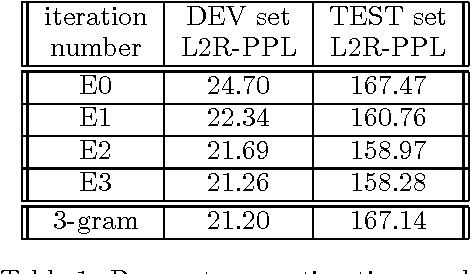
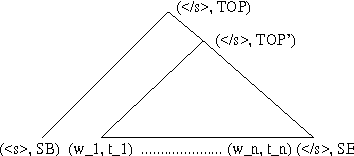

The paper presents a language model that develops syntactic structure and uses it to extract meaningful information from the word history, thus enabling the use of long distance dependencies. The model assigns probability to every joint sequence of words--binary-parse-structure with headword annotation and operates in a left-to-right manner --- therefore usable for automatic speech recognition. The model, its probabilistic parameterization, and a set of experiments meant to evaluate its predictive power are presented; an improvement over standard trigram modeling is achieved.
* changed ACM-class membership and buggy author names
Recognition Performance of a Structured Language Model
Jan 24, 2000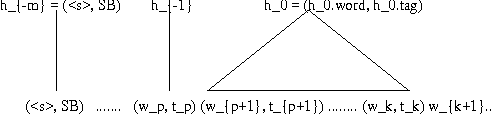
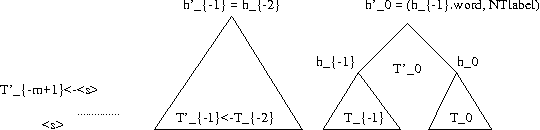

A new language model for speech recognition inspired by linguistic analysis is presented. The model develops hidden hierarchical structure incrementally and uses it to extract meaningful information from the word history - thus enabling the use of extended distance dependencies - in an attempt to complement the locality of currently used trigram models. The structured language model, its probabilistic parameterization and performance in a two-pass speech recognizer are presented. Experiments on the SWITCHBOARD corpus show an improvement in both perplexity and word error rate over conventional trigram models.
* 4 pages
Refinement of a Structured Language Model
Jan 24, 2000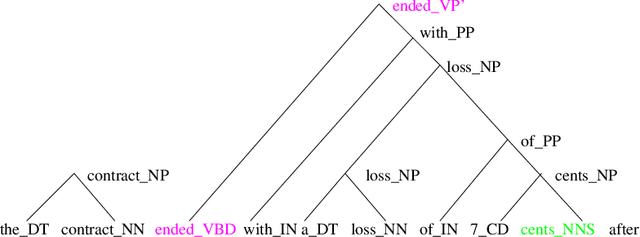
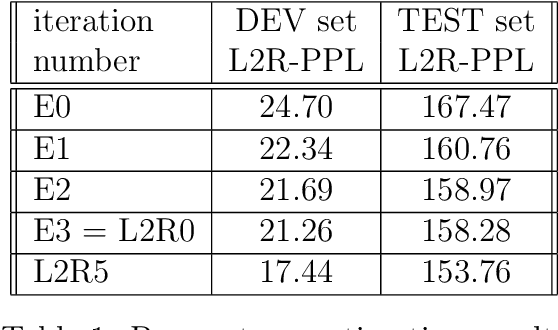
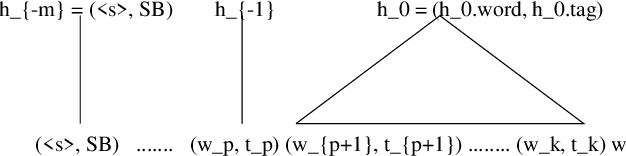
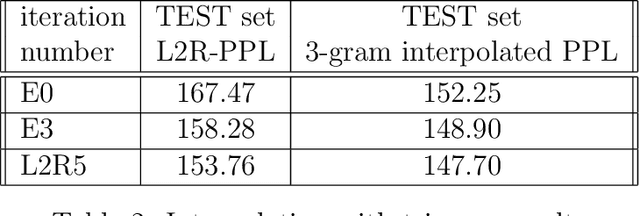
A new language model for speech recognition inspired by linguistic analysis is presented. The model develops hidden hierarchical structure incrementally and uses it to extract meaningful information from the word history - thus enabling the use of extended distance dependencies - in an attempt to complement the locality of currently used n-gram Markov models. The model, its probabilistic parametrization, a reestimation algorithm for the model parameters and a set of experiments meant to evaluate its potential for speech recognition are presented.
* 10 pages